Peer Discovery: Find 20 Swiss Companies Like Yours (and Benchmark Against Them)
Two related questions come up constantly in Swiss market research: "Who looks like this company?" and "How does this company compare to its peers?" The VynCo SDK has dedicated endpoints for both, and running them end-to-end is about 20 lines.
Find similar companies
import vynco
client = vynco.Client()
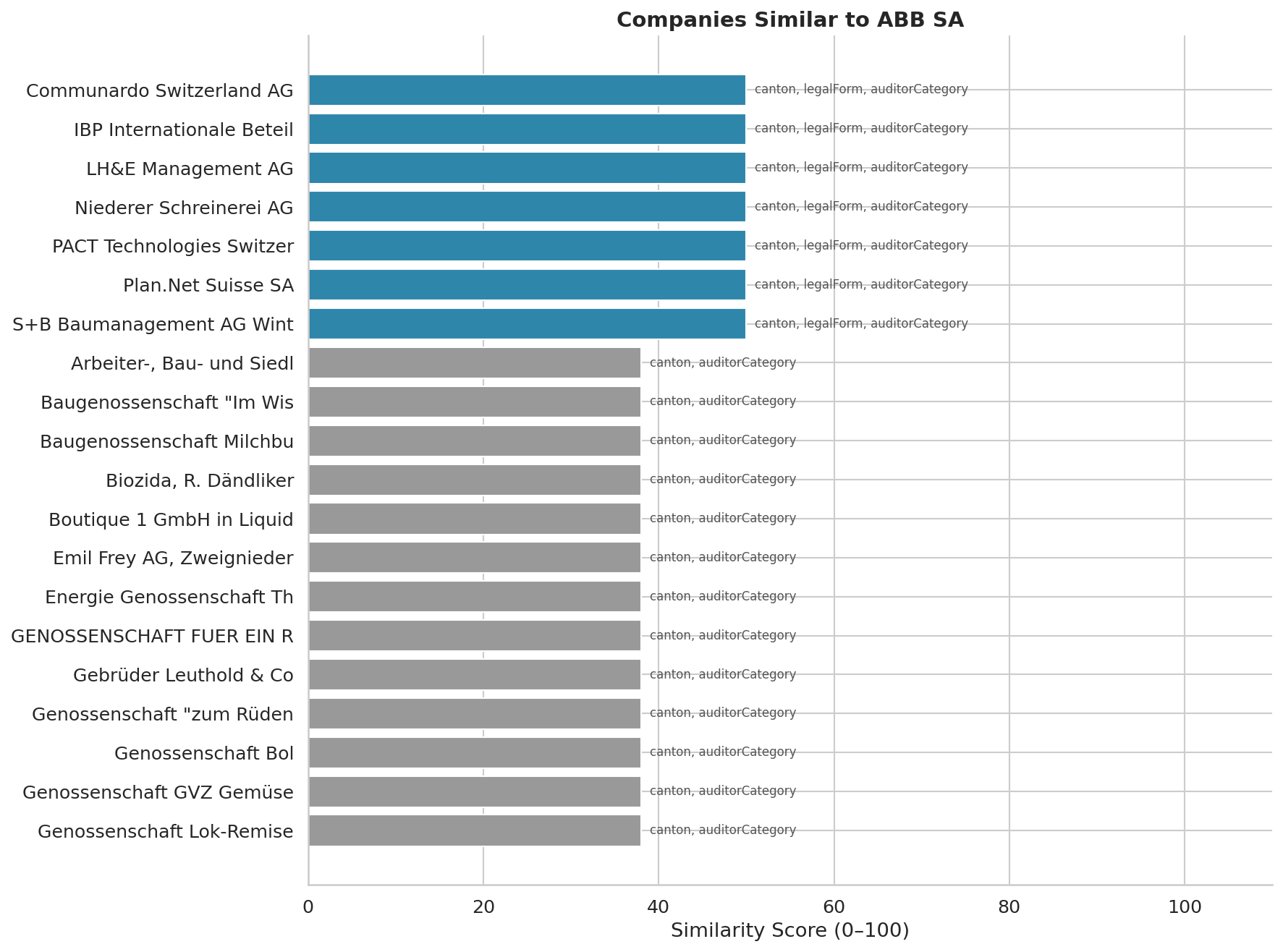
similar = client.companies.similar("CHE-105.805.080", limit=20).data
for c in similar.results:
dims = ", ".join(c.matching_dimensions)
print(f"{c.similarity_score:>3}/100 {c.name:<50} [{dims}]")
The similarity score (0-100) is computed over six dimensions:
| Dimension | Max | Fires when |
|---|---|---|
| industry | 40 | exact industry match |
| canton | 20 | same canton |
| share capital | 20 | within 50%; 10 points within 200% |
| legal form | 10 | same legal form (AG, GmbH, etc.) |
| auditor category | 10 | same Big-4 / MidTier / Small classification |
| name tokens | 10-20 | shared significant tokens (e.g., "UBS" appearing in both names) |
The scorer normalises to the target's eligible max — if the target's industry is null (which is common for major Swiss corporates with thin Zefix data), the 40 industry points are redistributed across the remaining dimensions, so scores remain meaningful instead of stuck at 40/100.
The matching_dimensions field tells you why each candidate ranked where it did, which is usually more interesting than the score itself.
Then benchmark
The analytics.benchmark() endpoint takes the same target UID and returns percentile ranks across capital, board size, change frequency, and company age against its peer cohort:
bench = client.analytics.benchmark(uid="CHE-105.805.080").data
for d in bench.dimensions:
if d.percentile is None:
print(f"{d.name:<20} insufficient peer data ({d.peers_with_data} peers)")
else:
print(f"{d.name:<20} {d.company_value:>15,.0f} "
f"median={d.industry_median:,.0f} "
f"{d.percentile:>5.1f}th percentile")
The endpoint returns None for percentiles where the peer cohort lacks enough usable data (for capital, we filter 0-valued peers as missing — most small Swiss GmbHs don't have share_capital recorded). That's deliberate: we'd rather return "insufficient data" than a misleading 0th percentile.
Tie handling uses the midrank method — a company tied with the median lands at ~50th percentile, not 0th, which is a common bug in hand-rolled percentile implementations.
Three things this unlocks
1. Competitive landscape maps
Take your own UID, pull the top 50 similar companies, and plot them on a 2D canvas by share_capital × board_size:
peers = client.companies.similar(my_uid, limit=50).data.results
# ... plot in matplotlib / plotly / d3
You now have a quantitative answer to "who are our peers" that doesn't rely on a salesperson's memory.
2. B2B sales prospecting
Sales teams often want to find "100 more companies like our best customer." The similar_companies.ipynb notebook turns that into a CSV export suitable for a CRM import:
rows = []
for seed_uid in top_customers:
for peer in client.companies.similar(seed_uid, limit=30).data.results:
if peer.similarity_score >= 60:
rows.append({"uid": peer.uid, "name": peer.name, "seed": seed_uid,
"score": peer.similarity_score})
Cap at score ≥ 60 and you're targeting genuinely-matching companies, not just "anything in the same canton".
3. Investor due diligence
For private equity / VC sourcing: pull the benchmark, check whether your target is an outlier in a way that's interesting (100th-percentile board size for its industry? often indicates a holding-company structure) or suspicious (0th-percentile change frequency? stagnant or dormant).
The benchmark detail table figure in the notebook shows all of this at once.
Honest limits on data
- The similarity-score ceiling depends on industry-data coverage. Industry is populated for ~13% of companies today. The new industry_classification pipeline runs every 2 hours and backfills industries via LLM (closed 30-label taxonomy, confidence-scored), so coverage will rise quickly.
- The benchmark requires ≥ 5 peers with data to compute a percentile. Small or highly-specialized cohorts will legitimately return null — the SDK types this as
float | Noneso your code can branch explicitly.
Run it
pip install vynco
export VYNCO_API_KEY=vc_live_...
python examples/quickstart.py
The similar_companies.ipynb notebook renders the radar + table figures end-to-end in about 10 seconds.
Links
- Notebook: similar_companies.ipynb
- API reference: /docs/similar, /docs/benchmark
- Get an API key: vynco.ch/signup